Understanding AI: Clarifying Concepts Behind Everyday Interactions
We interact with AI systems daily, from asking ChatGPT questions to getting recommendations on streaming platforms. But despite this familiarity, there might be some struggle in understanding what artificial intelligence actually is and how it works.

Understanding AI: Beyond the Chatbot Hype

In our modern world, the terms "AI," "machine learning," "neural networks," and "large language models" are popping up everywhere, potentially creating confusion about what's really happening behind the scenes.
This blog post will (maybe) help demystify these concepts, explaining not just what they are, but how they relate to each other and work together to create the intelligent systems we use today.
What is Artificial Intelligence, Really?
Artificial Intelligence is fundamentally about creating systems that can perform tasks typically requiring human intelligence. This includes reasoning, learning, perceiving patterns, understanding language, and making decisions. However, AI isn't a single technology but rather a broad field encompassing various approaches and techniques.
The key insight is that AI systems don't think like humans do. Instead, they use mathematical and statistical methods to process information and generate responses that appear intelligent. When you ask a chatbot a question, it's not "understanding" your words in the way humans do. Rather, it's performing complex calculations to predict the most appropriate response based on patterns learned from vast amounts of data.

Modern AI can be categorized into narrow AI and general AI. Narrow AI, which includes all current AI systems, excels at specific tasks like language translation, image recognition, or playing chess. General AI, which remains theoretical, would match human cognitive abilities across all domains. Every AI system you encounter today, including the most sophisticated chatbots, falls into the narrow AI category.
Machine Learning: The Engine of Modern AI
Machine learning is the primary method by which modern AI systems acquire their capabilities, building on earlier probabilistic techniques like Markov Chains that modeled state transitions and sequences. Rather than programming explicit rules for every possible scenario, machine learning allows systems to learn patterns from data and make predictions about new, unseen situations.
Think of machine learning as teaching a computer to recognize patterns the same way you might learn to identify different dog breeds. Instead of memorizing a list of characteristics for each breed, you'd look at thousands of photos, gradually learning to distinguish features that differentiate a Golden Retriever from a German Shepherd. Machine learning works similarly, but with mathematical precision and the ability to process far more data than any human could handle.
There are three main types of machine learning approaches. Supervised learning uses labeled examples to train models, like showing the system thousands of photos labeled "cat" or "dog" to teach it the difference. Unsupervised learning finds hidden patterns in data without explicit labels, such as grouping customers by purchasing behavior without being told what groups to look for. Reinforcement learning teaches systems through trial and error, rewarding good decisions and penalizing poor ones, much like training a pet with treats.
The power of machine learning lies in its ability to generalize. A well-trained model can make accurate predictions about data it has never seen before, which is what enables AI systems to handle the endless variety of real world situations they encounter.
Markov Chains: A Probabilistic Foundation
Before the rise of neural networks and deep learning, many early AI systems relied on simpler probabilistic models to understand and generate sequences. One of the most important of these foundational tools is the Markov Chain, a mathematical system that transitions from one state to another based on a fixed set of probabilities.
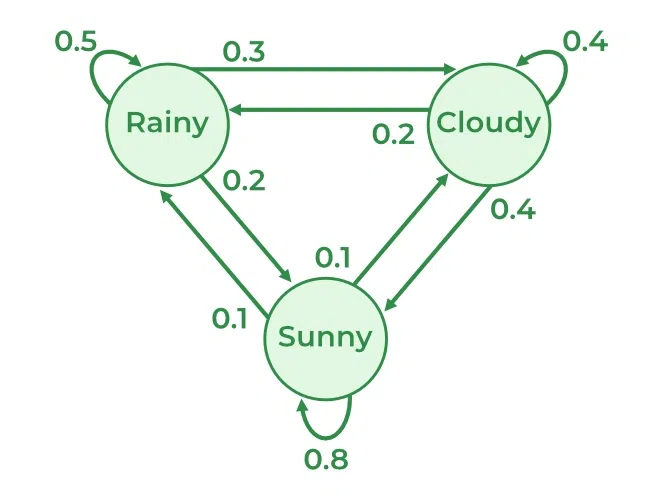
The core idea behind a Markov Chain is both powerful and surprisingly simple: the next state of the system depends only on the current state, not on the sequence of events that came before it. This is known as the Markov property. Imagine you're trying to predict tomorrow’s weather. A Markov model might say: “If today is sunny, there's a 70% chance it will also be sunny tomorrow, and a 30% chance it will rain.” The model doesn't care what the weather was two days ago, it only considers the current condition.
Markov Chains were particularly influential in early Natural Language Processing (NLP). They allowed computers to generate or analyze sequences of words by treating each word as a “state” and learning the likelihood of one word following another. For example, in a simple bigram model trained on text, if the word “artificial” is frequently followed by “intelligence”, the system learns to predict that sequence with high probability.
While limited in complexity, these models laid essential groundwork. They demonstrated how computers could learn structure from data without being explicitly programmed with grammar rules or logic. However, Markov Chains have major limitations: they struggle with long-range dependencies and can't capture deep meaning or context. This is why they were eventually eclipsed by more sophisticated models like recurrent neural networks and transformers.
Still, Markov Chains remain relevant. They’re widely used in fields like bioinformatics, finance, robotics, and game AI. They’re also an excellent teaching tool for understanding how AI systems model uncertainty and sequences. Even today’s most advanced models, such as large language models, rely on concepts rooted in probability and state transitions, just with much more depth and complexity than traditional Markov Chains could manage.
Neural Networks: Inspired by the Brain
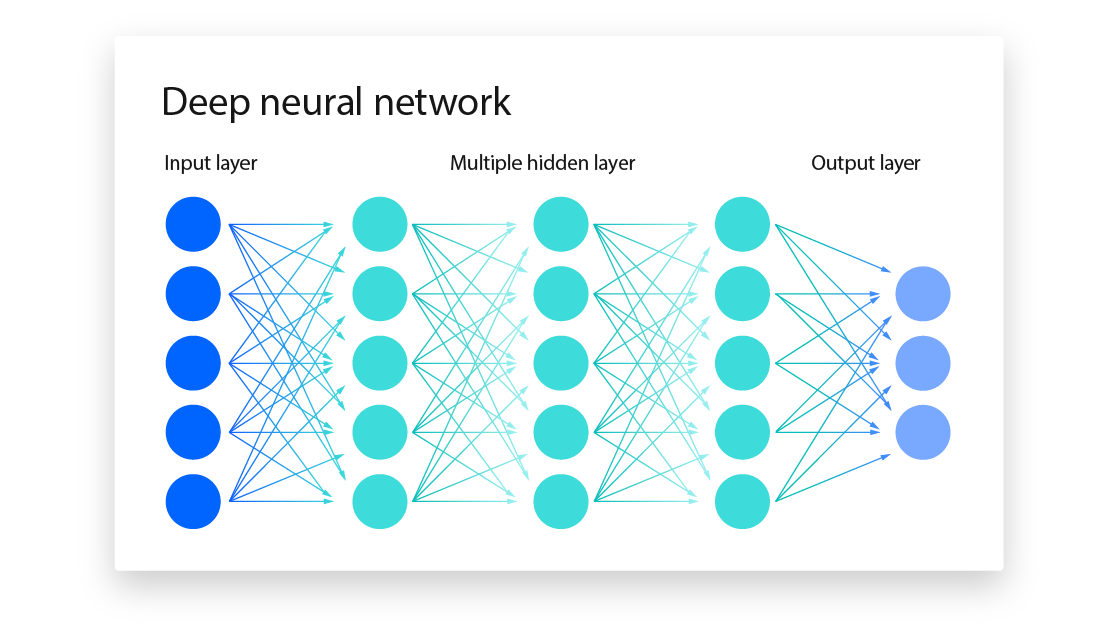
Neural networks represent one of the most successful approaches to machine learning, loosely inspired by how biological brains process information. However, it's important to understand that artificial neural networks are mathematical abstractions rather than biological simulations.
A neural network consists of interconnected nodes, called neurons, organized in layers. Each connection between neurons has a weight that determines how strongly one neuron influences another. When information enters the network, it flows through these connections, with each neuron performing simple calculations on the data it receives.
The magic happens during training. The network starts with random weights, making essentially random predictions. As it processes training data, it compares its predictions to the correct answers and adjusts the weights to reduce errors. This process, called backpropagation, continues across millions or billions of examples until the network learns to recognize complex patterns.
What makes neural networks particularly powerful is their ability to learn hierarchical representations. In image recognition, for example, early layers might detect simple features like edges and corners, middle layers combine these into shapes and textures, and later layers recognize complete objects like faces or cars. This hierarchical learning mirrors how human visual processing works, though the underlying mechanisms are entirely different.
Deep learning refers to neural networks with many layers, typically more than three or four. These deep networks can learn increasingly sophisticated representations, which is why they've been so successful in tasks like image recognition, natural language processing, and speech synthesis.
How AI Actually "Reads": The Vector Revolution
Here's where things get particularly fascinating and technical. AI systems don't actually read words the way humans do. Instead, they convert everything into mathematical representations called vectors: arrays of numbers that capture meaning in high-dimensional space.
Word Embeddings: From Text to Mathematics
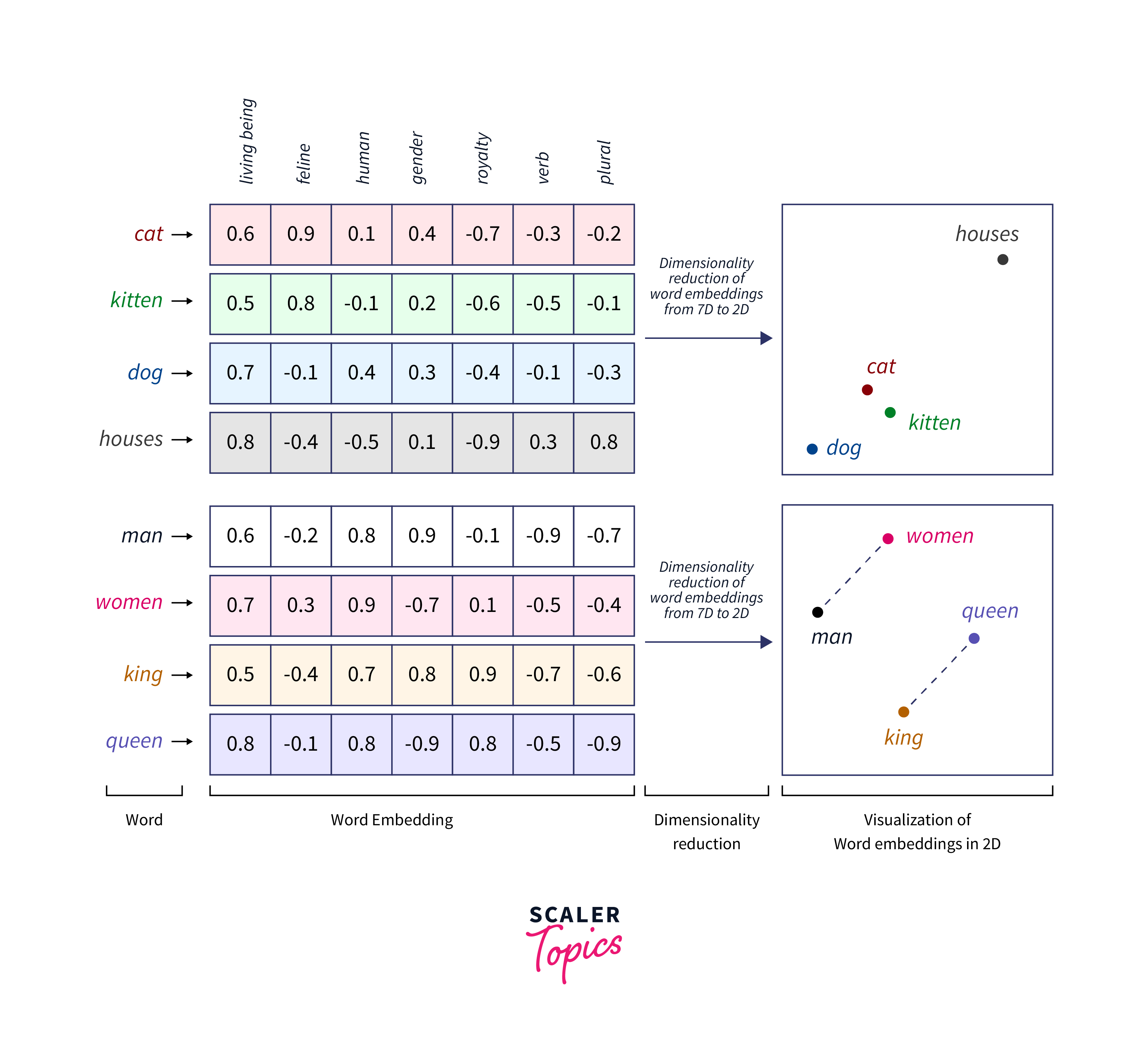
When you type "cat" into an AI system, it doesn't see the letters c-a-t. Instead, it instantly converts that word into a vector, perhaps something like [0.2, -0.5, 0.8, 0.1, -0.3, ...] extending across hundreds or thousands of dimensions. This process is called word embedding, and it's one of the most crucial breakthroughs in modern AI.
These vectors aren't random numbers. They're learned representations that capture semantic relationships between words. Words with similar meanings end up with similar vectors. The famous example is that the vector for "king" minus the vector for "man" plus the vector for "woman" approximately equals the vector for "queen." This mathematical relationship emerges naturally from training on large text datasets.
The Geometry of Meaning
What's remarkable is that these vector spaces develop a kind of geometry of meaning. Words cluster together in meaningful ways: all animal names group in one region, colors in another, verbs in yet another. The distance between vectors corresponds to semantic similarity - "dog" and "puppy" have vectors that are close together, while "dog" and "astronomy" are far apart.
This vector representation allows AI to perform mathematical operations on meaning itself. When an AI system processes your question about pets, it's not matching keywords but navigating through this multidimensional space of meaning, finding the most relevant paths through the conceptual landscape.
Context Vectors and Attention
Modern systems go beyond simple word vectors. They create contextual embeddings where the same word gets different vector representations depending on its context. The word "bank" has different vectors when referring to a financial institution versus a river bank. This context-sensitivity is achieved through attention mechanisms that allow the model to focus on relevant parts of the input when determining each word's meaning.
Multimodal Vectors: Beyond Text
The vector approach extends beyond language. Images, audio, and even video get converted into vectors in their own high-dimensional spaces. Remarkably, advanced AI systems learn to map different types of content into shared vector spaces, which is why a model like DALL-E can understand text descriptions and generate corresponding images. It's finding connections between text vectors and image vectors in a unified mathematical space.
Natural Language Processing: Teaching Machines to Understand Human Language
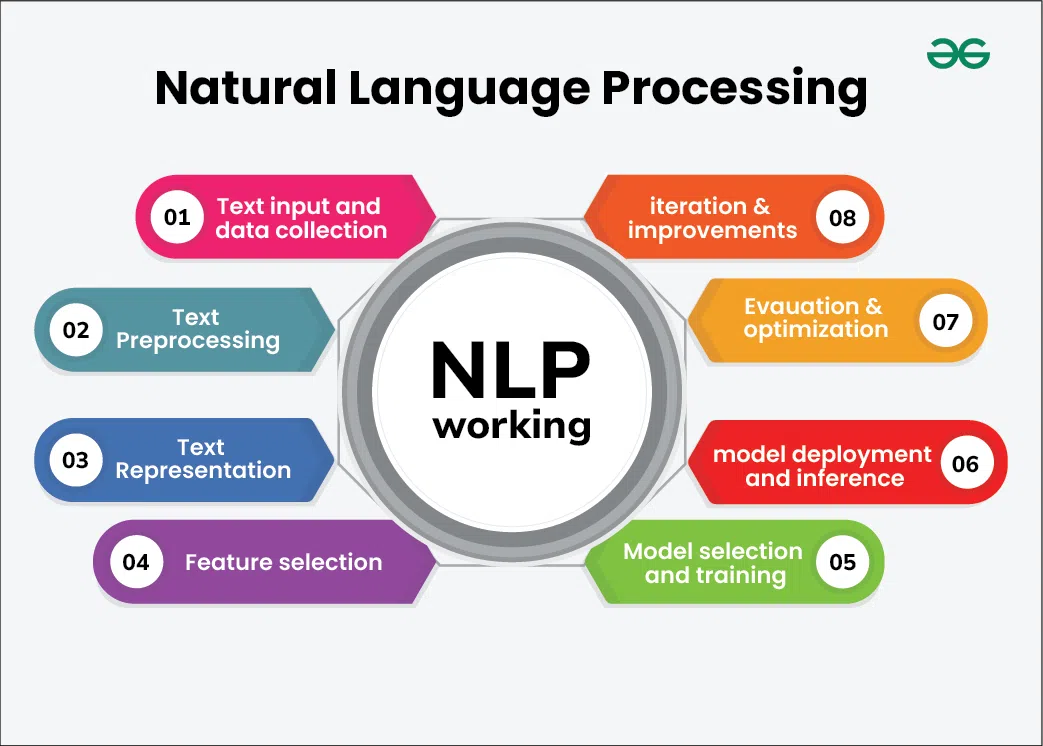
Natural Language Processing, commonly abbreviated as NLP, represents one of the most challenging and important applications of AI. It focuses on enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful. While we often take our ability to understand language for granted, it's actually an incredibly complex cognitive task that involves syntax, semantics, context, cultural knowledge, and subtle implications.
The challenge of NLP becomes apparent when you consider the ambiguity inherent in human language. A simple sentence like "I saw her duck" could mean you observed someone quickly lower their head, or you spotted a waterfowl that belongs to a female person. Humans resolve such ambiguities effortlessly using context, but teaching machines to do the same requires sophisticated algorithms and vast amounts of training data.
Traditional NLP approaches relied heavily on rule-based systems and linguistic expertise. Researchers would manually encode grammar rules, create dictionaries of word meanings, and develop algorithms to parse sentence structure. While these methods worked for simple tasks, they struggled with the complexity and variability of real world language use. They couldn't handle slang, metaphors, cultural references, or the countless exceptions that make human language so rich and expressive.
The field transformed dramatically with the application of machine learning techniques. Instead of programming explicit rules, modern NLP systems learn language patterns from enormous datasets of text. This shift enabled much more robust and flexible language understanding, capable of handling the messy, inconsistent nature of how people actually communicate.
The Tokenization Process: Breaking Down Language
Before any AI system can process text, it must first break it down into manageable pieces through a process called tokenization. This isn't as simple as splitting text by spaces, modern tokenizers use sophisticated algorithms to identify meaningful units that might be whole words, parts of words, or even individual characters.
Subword tokenization has become particularly important for handling the vast vocabulary of human language efficiently. Instead of needing separate tokens for "walk," "walking," "walked," and "walks," a subword tokenizer might break these into "walk" + "ing," "walk" + "ed," and "walk" + "s." This approach dramatically reduces the vocabulary size while maintaining the ability to handle new or rare words.
Positional Encoding: Understanding Word Order
Unlike humans, neural networks don't naturally understand that word order matters. The sentence "The dog bit the man" means something very different from "The man bit the dog," but a basic neural network would see these as the same collection of words. To solve this, AI systems use positional encoding: mathematical techniques that embed information about each word's position directly into its vector representation.
NLP encompasses numerous specific tasks, each presenting unique challenges. Machine translation converts text from one language to another, requiring deep understanding of both linguistic structures and cultural contexts. Sentiment analysis determines the emotional tone of text, crucial for understanding customer feedback or social media posts. Named entity recognition identifies specific items like people, places, or organizations within text. Question answering systems, like those powering search engines, must understand queries and locate relevant information. Text summarization condenses long documents while preserving key information.
The relationship between NLP and the other technologies we've discussed is intimate and evolving. Neural networks revolutionized NLP by enabling systems to learn complex language representations automatically. The transformer architecture, which we mentioned in the context of LLMs, was actually developed specifically for NLP tasks and later adapted for other domains. Generative AI techniques now power many NLP applications, from chatbots that can engage in natural conversation to systems that can write coherent articles or code.
What makes modern NLP particularly powerful is its ability to capture not just the literal meaning of words, but their contextual relationships and subtle implications. When a language model processes the phrase "The movie was absolutely terrible," it doesn't just recognize the individual words but understands the sentiment, the emphasis created by "absolutely," and the cultural context that makes this a negative review rather than a positive one.
Generative AI: Creating Rather Than Just Analyzing
Before diving into Large Language Models, it's important to understand the broader category they belong to: Generative Artificial Intelligence, or GenAI. This represents a fundamental shift in how we think about AI capabilities.
Traditional AI systems were primarily focused on analysis and classification. They could recognize images, categorize emails as spam, or predict stock prices, but they couldn't create new content. Generative AI changes this paradigm entirely by creating new, original content that didn't exist in the training data.
GenAI encompasses various types of content creation. Text generation models can write articles, poems, or code. Image generation systems like DALL-E, Midjourney, and Stable Diffusion can create artwork from text descriptions. Audio generation models can compose music or synthesize speech. Video generation systems are beginning to create short clips and animations.
The Mathematics of Creativity
What makes generative AI particularly fascinating is that it's not simply copying and pasting from existing content. Instead, these systems learn the underlying patterns and structures of their training data, then use that knowledge to create something genuinely new. When an AI generates an image of "a purple elephant wearing a top hat," it's combining concepts it learned separately to create something that likely never existed in its training data.
The key breakthrough enabling modern GenAI came from learning probability distributions over the training data. These systems model the likelihood of different possibilities and then sample from these learned distributions to generate new content. This probabilistic approach is why you can ask the same generative AI system the same question multiple times and receive different, but equally valid, responses.
Diffusion Models: The Art of Gradual Creation
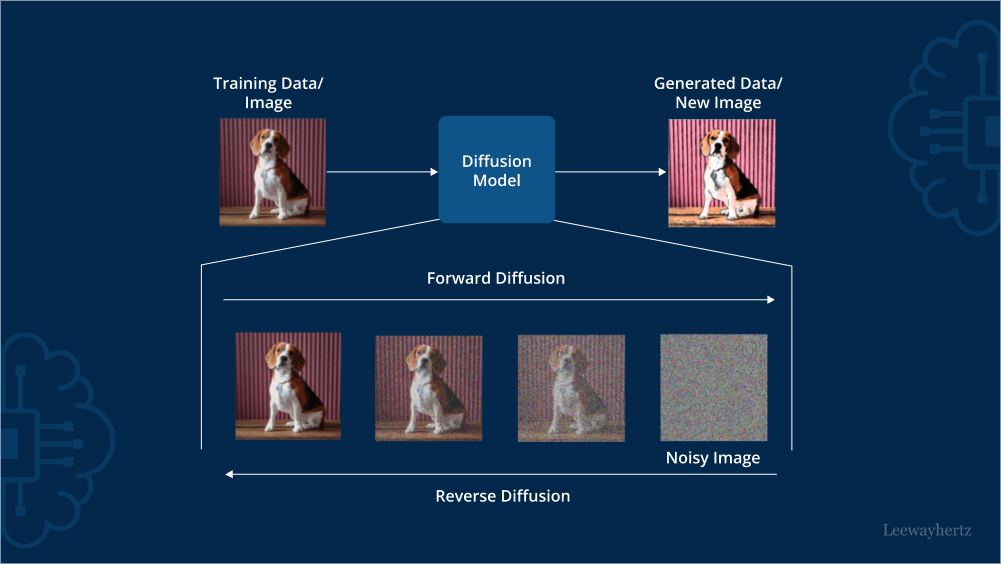
One of the most successful approaches to image generation uses diffusion models, which work by learning to reverse a noise-adding process. During training, these models learn to remove noise from increasingly corrupted images. At generation time, they start with pure noise and gradually "denoise" it into a coherent image, guided by text prompts or other conditions. This process is remarkably similar to how an artist might start with rough sketches and gradually refine them into detailed artwork.
Variational Autoencoders and GANs
Other generative approaches include Variational Autoencoders (VAEs), which learn to compress data into a lower-dimensional representation and then reconstruct it, and Generative Adversarial Networks (GANs), which pit two neural networks against each other: one trying to generate realistic content and another trying to detect fakes. This adversarial training often produces remarkably realistic results, though it can be unstable and difficult to train.
Large Language Models: The Foundation of Modern Chatbots
Large Language Models represent the most prominent and widely-used application of both generative AI and natural language processing, specifically focused on understanding and generating human language. These models, which power systems like ChatGPT, Claude, and Google's Bard, are trained on enormous amounts of text data to learn the statistical patterns of human language.
The "large" in LLM refers to both the amount of training data and the number of parameters in the neural network. Modern LLMs contain hundreds of billions of parameters, each representing a learned aspect of language. These parameters capture everything from basic grammar rules to complex relationships between concepts, cultural references, and reasoning patterns.
LLMs work by predicting the next word in a sequence. During training, they process trillions of words from books, articles, websites, and other text sources, learning to predict what word should come next given the preceding context. This seemingly simple task requires the model to develop sophisticated understanding of syntax, semantics, world knowledge, and reasoning.
The Transformer Revolution
The transformer architecture, introduced in 2017, revolutionized LLMs by enabling them to process all words in a sequence simultaneously rather than one at a time. This parallel processing, combined with attention mechanisms that help the model focus on relevant parts of the input, dramatically improved both training efficiency and model performance.
The key innovation of transformers is the self-attention mechanism. When processing a sentence, the model computes attention scores between every pair of words, allowing it to understand complex relationships regardless of distance. In the sentence "The cat that lived in the house with the red door was hungry," the model can directly connect "cat" with "was hungry" despite the intervening words.
Scaling Laws and Emergent Abilities
One of the most surprising discoveries in LLM research is that many capabilities emerge suddenly as models get larger. Small models might struggle with basic arithmetic, while slightly larger ones can solve complex word problems. This isn't gradual improvement but rather threshold effects where new abilities appear almost overnight as computational scale increases.
These scaling laws suggest that intelligence might be more about computation and data than previously thought. However, we're beginning to hit limits in terms of available text data and computational resources, leading researchers to explore more efficient training methods and better data utilization.
Training Phases: From Language Modeling to Conversation
Modern LLMs undergo multiple training phases. The initial pre-training phase teaches the model to predict next words on massive text datasets. This is followed by supervised fine-tuning on high-quality examples of desired behavior, and then reinforcement learning from human feedback (RLHF) to align the model's responses with human preferences.
This multi-stage process is why modern chatbots can engage in helpful, harmless conversations rather than simply mimicking the often chaotic nature of internet text. The fine-tuning process teaches them to be assistants rather than just text predictors.
What's remarkable about LLMs is how this next word prediction training leads to emergent capabilities. Models trained only to predict text can engage in conversations, answer questions, write code, solve math problems, and perform many other tasks that weren't explicitly programmed. These abilities arise from the complex patterns learned during training, though researchers are still working to fully understand how and why this happens.
Advanced Architectural Innovations
Mixture of Experts (MoE)
One breakthrough in scaling AI systems efficiently is the Mixture of Experts architecture. Instead of routing all inputs through the entire network, MoE models contain multiple specialized "expert" networks and learn to route different types of inputs to the most appropriate experts. This allows for much larger total model capacity while keeping computational costs manageable, since only a subset of the model is active for any given input.
Retrieval-Augmented Generation (RAG)
To address the limitation that LLMs only know information from their training data, Retrieval-Augmented Generation systems combine language models with search capabilities. When asked a question, these systems first search through external knowledge bases or documents, then use the retrieved information to inform their response. This approach allows AI systems to access up-to-date information and cite specific sources.
Constitutional AI and AI Safety
As AI systems become more powerful, ensuring they behave safely and helpfully becomes crucial. Constitutional AI is an approach where models are trained using a set of principles or "constitution" that guides their behavior. Instead of relying solely on human feedback, these systems learn to critique and revise their own outputs according to these principles, potentially scaling oversight to match AI capabilities.
How It All Connects: The AI Ecosystem

Understanding how these concepts relate to each other is crucial for grasping modern AI. Artificial Intelligence is the overarching goal of creating intelligent systems. Machine learning provides the methodology for achieving this goal by learning from data rather than explicit programming. Neural networks offer a powerful architecture for implementing machine learning algorithms. Vector representations provide the mathematical foundation that allows all these systems to work with meaning computationally.
Natural Language Processing represents a specific domain of AI focused on language understanding and generation. Generative AI represents a category of applications focused on content creation. Large Language Models are a specific type of generative AI that applies advanced NLP techniques to text generation and language understanding.
When you interact with a chatbot, you're experiencing the culmination of all these technologies working together. Your question is first tokenized and converted into vectors. These vectors flow through a transformer-based neural network that uses attention mechanisms to understand context and relationships. The model then generates probability distributions over possible next tokens, sampling from these distributions to create a response. The entire system represents both narrow AI designed for natural language interaction and a prime example of generative AI creating new text content.
The relationship extends beyond just language models. Image generation systems like DALL-E use similar neural network architectures but trained on image-text pairs to create visual content, often incorporating NLP techniques to understand text prompts. Music generation models apply these same principles to audio data. Voice assistants combine NLP for language understanding with speech recognition and synthesis. Recommendation systems combine multiple machine learning approaches to predict user preferences. Autonomous vehicles integrate various AI technologies, from computer vision for object detection to reinforcement learning for decision-making.
The Current Limitations and Future Directions
Despite their impressive capabilities, current AI systems have significant limitations. They lack true understanding in the human sense, instead relying on statistical correlations learned from training data. They can be inconsistent, generating different responses to the same question or failing on seemingly simple tasks while succeeding on complex ones.
The Hallucination Problem
LLMs, in particular, can "hallucinate" information, generating plausible-sounding but factually incorrect responses. This happens because these models are fundamentally prediction engines trained to produce coherent text, not truth-seeking systems. They can't distinguish between factual information and convincing-sounding fabrications in their training data.
Computational Limits and Efficiency
The computational requirements for training and running large AI models are enormous and growing. Training GPT-3 required thousands of high-end GPUs running for weeks, consuming megawatts of power. This raises questions about the environmental impact and accessibility of AI technology. Researchers are actively working on more efficient architectures, training methods, and deployment strategies.
Context Length and Memory
Current LLMs have limited context windows as they can only "remember" a certain number of recent tokens in a conversation. While this limit has grown from hundreds to hundreds of thousands of tokens, it still constrains the model's ability to maintain very long conversations or process extremely large documents. They also lack persistent memory between conversations and cannot learn from individual interactions.
The field continues to evolve rapidly. Researchers are working on making models more efficient, reducing computational requirements while maintaining performance. Efforts to improve reasoning capabilities focus on techniques like chain-of-thought prompting and integration with external tools. Multimodal models that can process text, images, audio, and video together represent another exciting frontier.
The development of more capable AI systems raises important questions about safety, alignment, and societal impact. As these technologies become more powerful and widespread, ensuring they remain beneficial and controllable becomes increasingly critical.
Practical Implications for Users
Understanding these underlying technologies can help you use AI tools more effectively. Recognizing that chatbots work through pattern matching and vector similarity rather than true understanding helps set appropriate expectations for their capabilities and limitations. Knowing that responses are generated through statistical prediction explains why the same question might yield different answers.
Understanding the vector-based nature of AI also explains why being specific in your prompts often works better, as you're helping the system navigate to the right region of its meaning space. When you provide context and examples, you're essentially giving the AI better coordinates in its multidimensional understanding of your request.
For businesses and developers, this knowledge is crucial for making informed decisions about AI implementation. Understanding the strengths and weaknesses of different approaches helps in choosing the right tools for specific problems and setting realistic expectations for AI-powered solutions.
As AI continues to advance, staying informed about these fundamental concepts will become increasingly important for everyone, from casual users to policy makers. The technology that powers our daily digital interactions is complex, but understanding its basic principles demystifies the seemingly magical capabilities of modern AI systems.
Conclusion

Artificial Intelligence, machine learning, neural networks, vector representations, natural language processing, generative AI, and large language models aren't just buzzwords but represent a hierarchy of increasingly specific technologies. AI provides the vision, machine learning offers the method, neural networks supply the architecture, vectors provide the mathematical foundation, NLP focuses on language understanding, generative AI enables content creation, and LLMs combine advanced NLP with generative capabilities to power the chatbots we use daily.
While these systems can seem almost magical in their capabilities, they're ultimately sophisticated statistical engines that excel at finding patterns in high-dimensional vector spaces and making predictions based on those patterns. The conversion of human language into mathematical vectors that capture meaning allows these systems to perform computations on concepts themselves, navigating through spaces of meaning to find relevant information and generate appropriate responses.
Understanding this fundamental nature - that AI works with mathematical representations of meaning rather than meaning itself - helps us appreciate both their remarkable achievements and their inherent limitations. These systems don't truly understand in the way humans do, but they've learned to manipulate the mathematical signatures of understanding with remarkable sophistication.
As AI continues to reshape our world, this foundational knowledge becomes essential for navigating a future where intelligent systems play an increasingly central role in our daily lives. The chatbot you casually interact with represents decades of research, billions of parameters, and vast vector spaces of learned meaning working together to simulate human-like conversation, even if the underlying process is fundamentally different from human thought.
References:
- https://arxiv.org/abs/1911.05755: An Introduction to Artificial Intelligence and Solutions to the Problems of Algorithmic Discrimination
- https://arxiv.org/abs/2504.08526: Hallucination, reliability, and the role of generative AI in science
- https://arxiv.org/abs/1901.05639: Machine learning with neural networks
- https://arxiv.org/abs/1404.7828: Deep Learning in Neural Networks: An Overview
- https://arxiv.org/abs/2208.11970: Understanding Diffusion Models: A Unified Perspective
- https://www.quantamagazine.org/will-ai-ever-understand-language-like-humans-20250501/: Will AI Ever Understand Language Like Humans?
- https://www.quantamagazine.org/chatbot-software-begins-to-face-fundamental-limitations-20250131/: Chatbot Software Begins to Face Fundamental Limitations
- https://www.ibm.com/think/topics/natural-language-processing: What is NLP (natural language processing)?
Read more at: Lazzerex’s Blog
Source: Published Notion page
This article
Post Reactions
Join the conversation
Write a Comment
Share your thought about this article.
Comments
Loading comments...